

Improving your LLMs with RLHF on Amazon SageMaker
AWS Machine Learning
SEPTEMBER 22, 2023
The technique operates by training a “reward model” based on human feedback and uses this model as a reward function to optimize an agent’s policy through reinforcement learning (RL). Gone are the days when you need unnatural prompt engineering to get base models, such as GPT-3, to solve your tasks. a written email).






































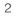
Let's personalize your content