


Connecting Amazon Redshift and RStudio on Amazon SageMaker
AWS Machine Learning
DECEMBER 29, 2022
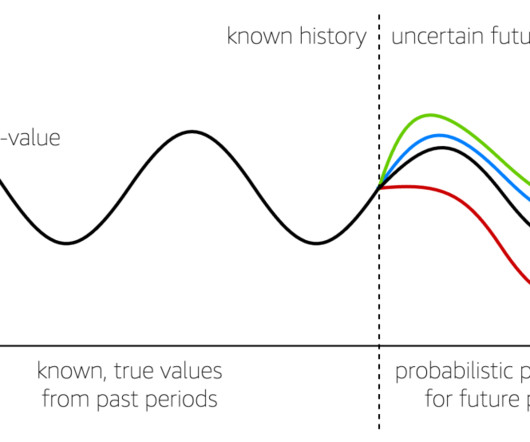
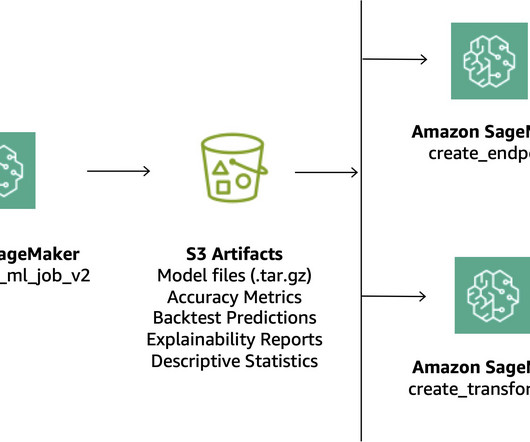
In this blog post, we will show you how to use both of these services together to efficiently perform analysis on massive data sets in the cloud while addressing the challenges mentioned above. In the blog today, we will be executing the following steps: Cloning the sample repository with the required packages. Solution overview.









Let's personalize your content