

Most Voice Analytics solutions for contact centers offer either Machine Learning-based or lexicon-based Sentiment Analysis to help you understand how customers are feeling during calls. But what is the difference between these two approaches and which one is better for your contact center?
As a Conversation Intelligence platform, MiaRec has helped hundreds of contact centers utilize Machine Learning-based Sentiment Analysis to drive digital transformation initiatives, such as strengthening customer experiences and achieving business goals.
In this article, you will learn about the differences between the Lexicon-based approach and Machine Learning-based Sentiment Analysis and how to use Sentiment Analysis to get the best Return-on-Investment (ROI) for your contact center.
What Is Sentiment Analysis?
Sentiment Analysis is the process of analyzing written or spoken texts to determine the emotional tone of the conversation. It measures subjectivity in text to understand how people are feeling toward a product, issue, event, service, or subject.
For contact centers, Sentiment Analysis scores your calls on whether they are positive, negative, or neutral to understand your Voice of Customer. It is a versatile tool that can enhance customer experiences, agent performances, and brand messaging. With Sentiment Analysis, you can leverage meaningful insights from your call transcripts to support business decisions, identify emerging trends, boost customer loyalty, and more.
What Is Lexicon-based Sentiment Analysis?
Lexicon-based Sentiment Analysis relies on an underlying sentiment lexicon to determine if the emotional tone of the text is positive, negative, or neutral. A sentiment lexicon is a manually created list of lexical features, usually words, which are labeled according to their semantic orientation as either positive or negative. Table 1 lists some of the widely used sentiment lexicons.
|
Lexicon |
No. of words and key phrases |
Lexicon type |
|
905 |
Polarity-based |
|
|
4,206 |
Polarity-based |
|
|
6,800 |
Polarity-based |
|
|
14,195 |
Polarity-based |
|
|
1,034 |
Valence-based |
|
|
147,306 |
Valence-based |
|
|
14,244 |
Valence-based |
|
|
7,500 |
Valence-based |
Table 1. Widely used sentiment lexicons
Words are typically categorized into binary classes (usually positive or negative). Some lexicons also assign a numerical score based on emotion intensity (also known as valence). For example, the word "okay" might have a positive valence of 0.9, "good" is 1.9, and "great" is 3.1, whereas "horrible" is -2.5, and "sucks" is -1.5. The actual score values depend on the lexicon. The sentiment score of a sentence in a document is typically calculated as a sum of individual word scores.
The sentiment lexicons usually consist of thousands of manually categorized words or key phrases. Most Sentiment Analysis solutions rely on the existing lexicons, as manually creating and validating sentiment lexicon would be incredibly labor-intensive and error-prone.
The benefit of Lexicon-based Sentiment Analysis is its simplicity and interpretability. The lexicon is directly accessible, meaning you can easily inspect, understand, extend, and modify it. Compared to Machine Learning-based Sentiment Analysis (which we will discuss later), Lexicon-based Sentiment Analysis is more interpretable because it is easy to identify the words that affected the final score and update each word score if necessary. With Machine Learning-based Sentiment Analysis, the scoring algorithm is hidden in a black-box, meaning it is not accessible to humans., and a quick correction to the algorithm is not possible
However, because it focuses on individual words, a Lexicon-based Sentiment Analysis does not take into account the context in which words are used. For example, the word “catch” has negative sentiment in, “At first glance, the contract looks good, but there is a catch”, but is neutral in, “The fisherman plans to sell his catch at the market”. Because of this ambiguity, most lexicons simply do not include words with context-dependent meaning, or they classify them as neutral. This also means Lexicon-based Sentiment Analysis tools are not capable of “understanding” sarcasm in human language.
Depending on the lexicon, some words can be classified differently. For example, in the paper A Deep Learning System for Sentiment Analysis of Service Calls by Yanan Jia, the author noted that “stunned” is a positive word in Bing, but a negative word in AFINN lexicon.
Lexicons are typically created for a certain domain, such as social media, movie, or product review platforms, and they perform worse when used for other domains, like telephone conversations. For example, A Deep Learning System for Sentiment Analysis of Service Calls study demonstrated that the VADER lexicon, which was originally created to measure sentiment in Twitter posts, was only 49.8% accurate when used on contact center service calls. Meanwhile, the ML-based model demonstrated over 85% accuracy on the same data.
Most sentiment lexicons were created for analyzing written texts, such as product reviews, social media posts, and more. They typically perform poorly when applied to spoken language, which is noisier than written language due to misapplied words, repetitions, inaccuracy in transcription, and more. There are no publicly available lexicons targeted to telephone conversations. Organizations have to create their own custom lexicons, which is time-consuming and requires constant maintenance. As new words or phrases, such as slang or acronyms, are used to convey emotions, you would have to constantly reconfigure lexicon to ensure accuracy.
What Is Machine Learning-based Sentiment Analysis?
Machine Learning-based Sentiment Analysis relies on the ability of machines to “learn” the sentiment-relevant features of the text. The idea is simple: if we input enough examples of positive, neutral, and negative sentences in the algorithm, then the machine would learn ways to identify sentiment in texts on its own.
Machine learning algorithms can be used in different areas, like computer vision, self-driving cars, speech recognition. In this article, we focus on training computer models capable of “understanding” the contents of texts, including the contextual nuances of the language within them. This subfield of Machine Learning is named Natural Language Processing, or NLP.
NLP-based Sentiment Analysis models can be trained to read beyond mere definitions, to understand things like context, sarcasm, and misapplied words. For example, take a look at the following movie review:
“By halfway through this picture I was beginning to hate it, and, of course, feeling guilty for it… Then, miracle of miracles, the movie does a flip-flop.”
Quote Source: Stanford Sentiment Treebank
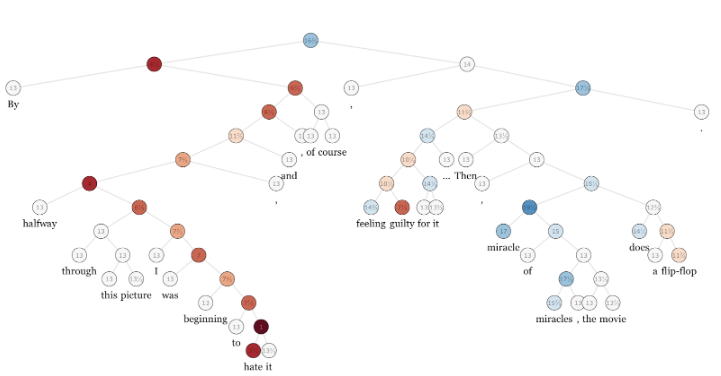
Figure 1. Example of the annotated review from the Stanford Sentiment Treebank
In this movie review, we can find more negative words than positive ones, yet the overall sentiment score is between neutral and positive. A simple approach of calculating negative and positive words would not be effective in this situation; it would inaccurately label this quote as a negative review.
There are a lot of spoken nuances, such as sarcasm, that can make it difficult to accurately quantify a sentence's sentiment score. The trained models consider context in order to properly identify sentiments in text.
According to More than a Feeling: Accuracy and Application of Sentiment Analysis by Hartmann, Heitmann, Siebert, and Schamp, Machine Learning-based Sentiment Analysis promises more accurate Sentiment Analysis by “automatically finding text classification rules based on a training data sample with human sentiment coding”.
One of the challenges when training Machine Learning-based Sentiment Analysis models is the need to prepare a lot of training data. Typically, to train a model from scratch, you need to prepare tens of thousands of samples for each sentiment class (positive, neutral and negative). It is very time-consuming to create datasets of such size.
There are a few publicly available datasets that can be used to train a Sentiment Analysis model (see Table 2), however the ones that are public are often not suitable for scoring telephone conversations. For example, a model trained on movie reviews will typically perform badly if used in a contact center environment.
|
Dataset |
Domain |
No of samples |
|
Amazon product reviews |
142,800,000 |
|
|
Rotten Tomatoes Movie reviews |
11,855 |
|
|
Amazon product reviews |
340,000 |
|
|
Movie reviews |
50,000 |
|
|
|
1,600,000 |
|
|
Financial news |
5,000 |
|
|
Amazon product reviews |
800,000 |
|
|
Yelp business reviews |
9,990,280 |
Table 2. Common datasets for training Sentiment Analysis models
Fortunately, a Sentiment Analysis model doesn’t have to be trained from scratch. Most companies today use the pre-trained NLP-models, like BERT, and fine-tune them to a Sentiment Analysis task. For instance, BERT has been trained on massive amounts of written texts, particularly on English Wikipedia (2,500M words) and BooksCorpus (800M words). This model has “learned” a lot of knowledge about human language; it learned the meaning of individual words, how to pay attention to context, how to understand sarcasm, and more.
The BERT model does not do Sentiment Analysis out of the box, but, with a bit of fine-tuning, it can be transformed into a state-of-the-art Sentiment Analysis model. To fine-tune a model, you typically need a couple hundred samples for each sentiment class (positive, neutral and negative). This is doable for most companies.
One of the benefits of this fine-tuning process is the ability to create a custom sentiment model that is specifically tailored to your organization’s needs. Every organization is different, and definitions of what counts as a negative and positive sentiment can differ as well.
Utilizing Sentiment Analysis To Get The Best ROI
To better illustrate how Voice Analytics solutions utilize Sentiment Analysis, we will be using MiaRec as an example.
MiaRec’s NLP-based Sentiment Analysis calculates a sentiment score for each conversation. You will receive a customer score, agent score, and total sentiment score.
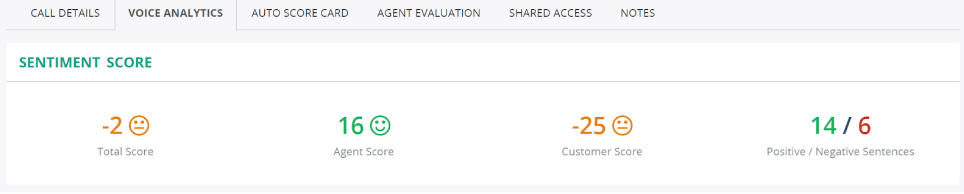
Figure 2. Sentiment score for conversation in the MiaRec platform.
Each phrase in a conversation is highlighted according to its sentiment score, either red (for very negative) or green (for very positive).
%20(1).png?width=624&height=156&name=Copy%20of%20Content%20Manager%20Job%20Description%20Template%20CTA%20Inline%20(1200%20%C3%97%20300%20px)%20(1).png)
Figure 3. Highlighted sentiments in the transcript in the MiaRec platform
Rather than manually defining “good” and “bad” words, MiaRec Sentiment Analysis uses a Machine Learning algorithm to assign positive or negative value to phrases for you. Machine Learning-based Sentiment Analysis is typically ready to use out-of-box, meaning there is no user setup needed. This also means you cannot customize your keywords or phrases. The algorithm decides for you what words or phrases are considered positive or negative. To alter the scoring algorithm, it is necessary to train a custom model on your own data.
Some Voice Analytic solutions, such as MiaRec, offer additional features which can work in tandem with Sentiment Analysis. While you cannot easily modify which words are positive or negative with Machine Learning-based Sentiment Analysis, you can customize which words you would like to track in Topics Analysis.
MiaRec Topics Analysis automatically categorizes calls by topics, making your call data organized and accessible. You can get the best ROI by using Topics and Sentiment Analysis together. By combining both features, you can see why customers called and how they felt throughout the call on a designated topic. These insights can then be used in marketing campaigns, personalizing experiences, evaluating agent performance, and more.
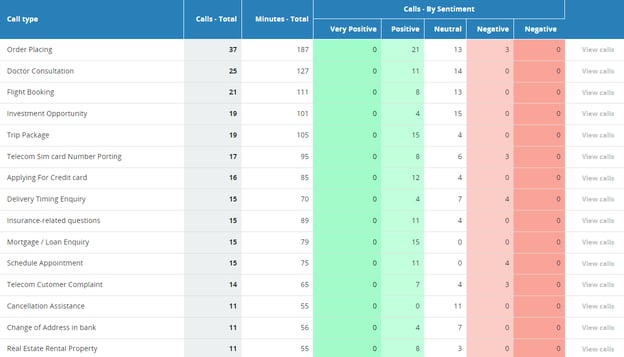
Figure 4. Topic analysis (call types) in the MiaRec platform
Contact center interactions are valuable pieces of data that can be used to measure how customers view your business, how agents are performing, and more. For example, you could review the sentiment score of all calls in your "Order Cancellation" topic. You could then identify any negative calls and use this feedback to train your agents and provide better customer service moving forward. This would improve your customer’s overall experience, increasing brand loyalty and decreasing customer churn.
You can also use Topics and Sentiment Analysis to monitor product feedback. You can set up a custom topic to track calls that mention new products or marketing campaigns. As you monitor the calls’ sentiment scores, you can gather customer reviews and feedback. With Sentiment and Topic Analysis, you can review customer and agent behavior without having to listen to the entire call.
These are just some of the ways you can use Topic and Sentiment Analysis to get the best ROI. For additional use cases, we recommend reading Top 6 Topic Analysis Use Cases For Any Contact Center.
Conclusion: Lexicon-based or Machine Learning-based Sentiment Analysis?
According to the study A Deep Learning System for Sentiment Analysis of Service Calls, Machine Learning-based Sentiment Analysis provides more accurate results than Lexicon-based Sentiment Analysis. As we discussed earlier, the popular Lexicon-based Sentiment Analysis tool VADER performed at 49.8% accuracy on contact center service calls, while the tested Machine Learning-based models performed at over 85% accuracy. It is important to mention that this study did not include more modern NLP architectures, which generally perform even better.
While Lexicon-based Sentiment Analysis has its uses in other industries, contact centers need to be able to thoroughly understand how customers are feeling throughout the call and why. These insights are essential for improving customer experiences, personalizing marketing campaigns, and more. Because of its accuracy and ability to measure conversations with more nuance, we recommend Machine Learning-based Sentiment Analysis over Lexicon-based Sentiment Analysis for contact centers.
However, some solutions might not clearly state what kind of Sentiment Analysis they offer. Always ask if it is not apparent. We also recommend asking contact center solutions how their solution utilizes Sentiment Analysis. Many Voice Analytics solutions offer additional features such as Topic Analysis which works alongside Sentiment Analysis to detect meaningful insights on how to improve agent performance, customer satisfaction, and business operations.
Try out Machine Learning-based Sentiment Analysis for yourself with MiaRec’s free online demo. See how Sentiment Analysis could transform how you understand customers and agents alike. Learn how your call data could drive successful business decisions and better your contact center workflows.


Share this

Are MiaRec’s Cloud-based Voice Analytics Solutions Secure?

Real-Time vs Post-Call Analytics: Benefits, Use Cases, & Differences
