AWS Machine Learning Blog
Retain original PDF formatting to view translated documents with Amazon Textract, Amazon Translate, and PDFBox
Companies across various industries create, scan, and store large volumes of PDF documents. In many cases, the content is text-heavy and often written in a different language and requires translation. To address this, you need an automated solution to extract the contents within these PDFs and translate them quickly and cost-efficiently.
Many businesses have diverse global users and need to translate text to enable cross-lingual communication between them. This is a manual, slow, and expensive human effort. There’s a need to find a scalable, reliable, and cost-effective solution to translate documents while retaining the original document formatting.
For verticals such as healthcare, due to regulatory requirements, the translated documents require an additional human in the loop to verify the validity of the machine-translated document.
If the translated document doesn’t retain the original formatting and structure, it loses its context. This can make it difficult for a human reviewer to validate and make corrections.
In this post, we demonstrate how to create a new translated PDF from a scanned PDF while retaining the original document structure and formatting using a geometry-based approach with Amazon Textract, Amazon Translate, and Apache PDFBox.
Solution overview
The solution presented in this post uses the following components:
- Amazon Textract – A fully managed machine learning (ML) service that automatically extracts printed text, handwriting, and other data from scanned documents that goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables. Amazon Textract can detect text in a variety of documents, including financial reports, medical records, and tax forms.
- Amazon Translate – A neural machine translation service that delivers fast, high-quality, and affordable language translation. Amazon Translate provides high-quality on-demand and batch translation capabilities across more than 2,970 language pairs, while decreasing your translation costs.
- PDF Translate – An open-source library written in Java and published on AWS Samples in GitHub. This library contains logic to generate translated PDF documents in your desired language with Amazon Textract and Amazon Translate. It also uses the open-source Java library Apache PDFBox to create PDF documents. There are similar PDF processing libraries available in other programming languages, for example Node PDFBox.
While performing machine translations, you may have situations where you wish to preserve specific sections of text from being translated, such as names or unique identifiers. Amazon Translate allows tag modifications, which allows you to specify what text should not be translated. Amazon Translate also supports formality customization, which allows you to customize the level of formality in your translation output.
For details on Amazon Textract limits, refer to Quotas in Amazon Textract.
The solution is restricted to the languages that can be extracted by Amazon Textract, which currently supports English, Spanish, Italian, Portuguese, French, and German. These languages are also supported by Amazon Translate. For the full list of languages supported by Amazon Translate, refer to Supported languages and language codes.
We use the following PDF to demonstrate translating the text from English to Spanish. The solution also supports generating the translated document without any formatting. The position of the translated text is maintained. The source and translated PDF documents can also be found in the AWS Samples GitHub repo.
In the following sections, we demonstrate how to run the translation code on a local machine and look at the translation code in more detail.

Prerequisites
Before you get started, set up your AWS account and the AWS Command Line Interface (AWS CLI). For access to any AWS Services such as Textract and Translate, appropriate IAM permissions are needed. We recommend utilizing least privilege permissions. To learn more about IAM permissions see Policies and permissions in IAM as well as How Amazon Textract works with IAM and How Amazon Translate works with IAM.
Run the translation code on a local machine
This solution focuses on the standalone Java code to extract and translate a PDF document. This is for easier testing and customizations to get the best-rendered translated PDF document. The code can then be integrated into an automated solution to deploy and run in AWS. See Translating PDF documents using Amazon Translate and Amazon Textract for a sample architecture that uses Amazon Simple Storage Service (Amazon S3) to store the documents and AWS Lambda to run the code.
To run the code on a local machine, complete the following steps. The code examples are available on the GitHub repo.
- Clone the GitHub repo:
- Run the following command:
- Run the following command to translate from English to Spanish:
Two translated PDF documents are created in the documents folder, with and without the original formatting (SampleOutput-es.pdf and SampleOutput-min-es.pdf).
Code to generate the translated PDF
The following code snippets show how to take a PDF document and generate a corresponding translated PDF document. It extracts the text using Amazon Textract and creates the translated PDF by adding the translated text as a layer to the image. It builds on the solution shown in the post Generating searchable PDFs from scanned documents automatically with Amazon Textract.
The code first gets each line of text with Amazon Textract. Amazon Translate is used to get translated text and save the geometry of the translated text.
The font size is calculated as follows and can easily be configured:
The translated PDF is created from the saved geometry and translated text. Changes to the color of the translated text can easily be configured.
The following image shows the document translated into Spanish with the original formatting (SampleOutput-es.pdf).
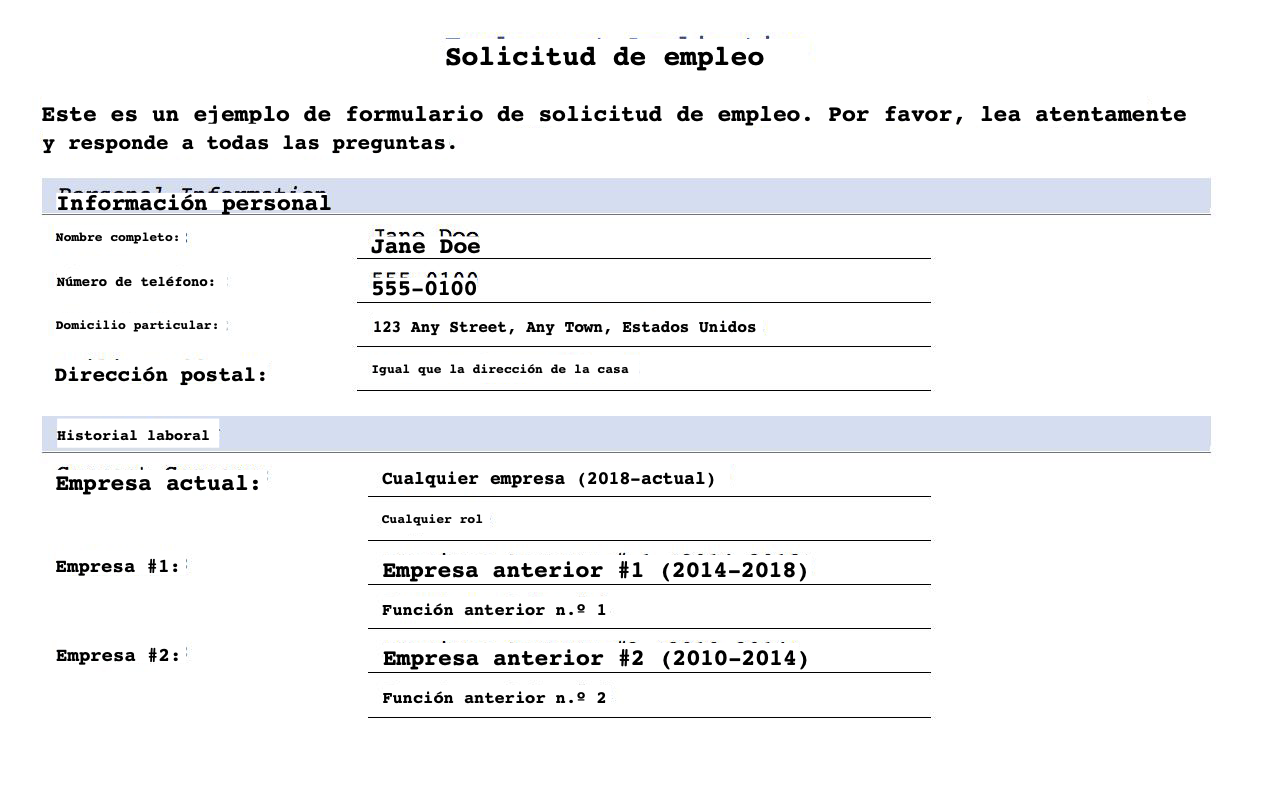
The following image shows the translated PDF in Spanish without any formatting (SampleOutput-min-es.pdf).

Processing time
The employment application pdf took about 10 seconds to extract, process and render the translated pdf. The processing time for text heavy document such as the Declaration of Independence PDF took less than a minute.
Cost
With Amazon Textract, you pay as you go based on the number of pages and images processed. With Amazon Translate, you pay as you go based on the number of text characters that are processed. Refer to Amazon Textract pricing and Amazon Translate pricing for actual costs.
Conclusion
This post showed how to use Amazon Textract and Amazon Translate to generate translated PDF documents while retaining the original document structure. You can optionally postprocess Amazon Textract results to improve the quality of the translation, for example extracted words can be passed through ML-based spellchecks such as SymSpell for data validation, or clustering algorithms can be used to preserve reading order. You can also use Amazon Augmented AI (Amazon A2I) to build human review workflows where you can use your own private workforce to review the original and translated PDF documents to provide more accuracy and context. See Designing human review workflows with Amazon Translate and Amazon Augmented AI and Building a multi-lingual document translation workflow with domain-specific and language-specific customization to get started.
About the Authors
 Anubha Singhal is a Senior Cloud Architect at Amazon Web Services in the AWS Professional Services organization.
Anubha Singhal is a Senior Cloud Architect at Amazon Web Services in the AWS Professional Services organization.
 Sean Lawrence was formerly a Front End Engineer at AWS. He specialized in front end development in the AWS Professional Services organization and the Amazon Privacy team.
Sean Lawrence was formerly a Front End Engineer at AWS. He specialized in front end development in the AWS Professional Services organization and the Amazon Privacy team.